

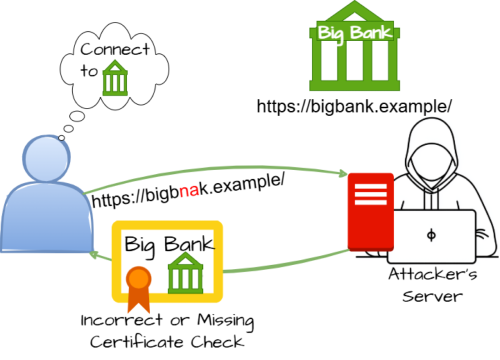
HTML code display: CWE-295_Improper_Certificate_Validation.png Haitian bulldog" Striim https://www.striim.com/ Thu, 06 Nov 2025 17:51:38 +0000 en-US hourly 1 https://wordpress.org/?v=6.8.2 https://media.striim.com/wp-content/uploads/2020/09/13183215/favicon-circle-157x150.png Striim https://www.striim.com/ 32 32 When Does Data Become a Decision? https://www.striim.com/blog/when-does-data-become-a-decision/ https://www.striim.com/blog/when-does-data-become-a-decision/#respond Thu, 06 Nov 2025 14:09:56 +0000 https://www.striim.com/?p=88690 For years, the mantra was simple: “Land it in the warehouse and we’ll tidy later.” That logic shaped enterprise data strategy for decades. Get the data in, worry about modeling, quality, and compliance after the fact.
The problem is, these days “later” usually means “too late.” Fraud gets flagged after the money is gone. A patient finds out at the pharmacy that their prescription wasn’t approved. Shoppers abandon carts while teams run postmortems. By the time the data looks clean on a dashboard, the moment it could have made an impact has already passed.
At some point, you have to ask: If the decision window is now, why do we keep designing systems that only prepare data for later?
This was the crux of our recent webinar, Rethinking Real Time: What Today’s Streaming Leaders Know That Legacy Vendors Don’t. The takeaway: real-time everywhere is a red herring. What enterprises actually need is decision-time: data that’s contextual, governed, and ready at the exact moment it’s used.
Define latency by the decision, not the pipeline
We love to talk about “real-time” as if it were an absolute. But most of the time, leaders aren’t asking for millisecond pipelines; rather, they’re asking to support a decision inside a specific window of time. That window changes with the decision. So how do we design for that, and not for some vanity SLA?
For each decision, write down five things:
Decision: What call are we actually making?
Window: How long before the decision loses value? Seconds? Minutes? Hours?
Regret: Is it worse to be late, or to be wrong?
Context: What data contributes to the decision?
Fallback: If the window closes, then what?
Only after you do this does latency become a real requirement. Sub-second pipelines are premium features. You should only buy them where they change the outcome, not spray them everywhere.
Satyajit Roy, CTO of Retail Americas at TCS, expressed this sentiment perfectly during the webinar.
Three latency bands that actually show up in practice
In reality, most enterprise decisions collapse into three bands.
Sub-second. This is the sharp end of the stick: decisions that have to happen in the flow of an interaction. Approve or block the card while the customer is still at the terminal. Gate a login before the session token issues. Adapt the price of an item while the shopper is on the checkout page. Miss this window, and the decision is irrelevant, because the interaction has already moved on.
Seconds to minutes. These aren’t interactive, but they’re still urgent. Think of a pharmacy authorization that needs to be resolved before the patient arrives at the counter. Or shifting inventory between stores to cover a shortfall before the next wave of orders. Or nudging a contact center agent with a better offer while they’re still on the call. You’ve got a small buffer, but the decision still has an expiration date.
Hours to days. The rest live here. Compliance reporting. Daily reconciliations. Executive dashboards. Forecast refreshes. They’re important, but the value doesn’t change if they show up at 9 a.m. sharp or sometime before lunch.
Keep it simple. You can think of latency in terms of these three bands, not an endless continuum where every microsecond counts. Most enterprises would be better off mapping decisions to these categories and budgeting accordingly, instead of obsessing over SLAs no one will remember.
From batch habits to in-stream intelligence
Once you know the window, the next question is harder: what actually flows through that window?
Latency alone doesn’t guarantee the decision will be right. If the stream shows up incomplete, out of context, or ungoverned, the outcome is still wrong, just… faster. For instance, when an AI agent takes an action, the stream it sees is the truth, whether or not that truth is accurate, complete, or safe.
This is why streaming can’t just be a simple transport layer anymore. It has to evolve into what I’d call a decision fabric: the place where enough context and controls exist to make an action defensible.
And if the stream is the decision fabric, then governance has to be woven into it. Masking sensitive fields, enforcing access rules, recording lineage, all of it has to happen in motion, before an agent takes an action. Otherwise, you’re just trusting the system to “do the right thing” (which is the opposite of governance).
Imagine a customer denied credit because the system acted on incomplete data, or a patient prescribed the wrong medication because the stream dropped a validation step. In these cases, governance is the difference between a system you can rely on and one you can’t.
Still, it has to be pragmatic. That’s the tradeoff enterprise leaders often face: how much assurance do you need, and what are you willing to pay for it? Governance that’s too heavy slows everything down. Governance that’s too light creates risk you can’t defend.
That balance—enough assurance without grinding the system to a halt—can’t be solved by policies alone. It has to be solved architecturally. And that’s exactly where the market is starting to split. Whit Walters, Field CTO at GigaOm, expressed this perfectly while explaining this year’s GigaOm Radar Report.
A true decision fabric doesn’t wait for a warehouse to catch up or a governance team to manually check the logs. It builds trust and context into the stream itself, so that when the model or agent makes a call, it’s acting on data you can stand behind.
AI is moving closer to the data
AI is dissolving the old division of labor. You can’t draw a clean line between “data platform” and “AI system” anymore. Once the stream itself becomes the place where context is added, governance is enforced, and meaning is made, the distinction stops being useful. Intelligence isn’t something you apply downstream. It’s becoming a property of the flow.
MCP is just one example of how the boundary has shifted. A function call like get_customer_summary is baked into the governed fabric. In-stream embeddings show the same move: they pin transactions to the context in which they actually occurred. Small models at the edge close the loop further still, letting decisions happen without exporting the data to an external endpoint for interpretation.
The irony is that many vendors still pitch “AI add-ons” as if the boundary exists. They talk about copilots bolted onto dashboards or AI assistants querying warehouses. Meanwhile, the real change is already happening under their feet, where the infrastructure itself is learning to think.
The way forward
Accountability is moving upstream. Systems no longer sit at the end of the pipeline, tallying what already happened. They’re embedded in the flow, making calls that shape outcomes in real time. That’s a very different burden than reconciling yesterday’s reports.
The trouble is, most enterprise architectures were designed for hindsight. They assume time to clean, model, and review before action. But once decisions are automated in motion, that buffer disappears. The moment the stream becomes the source of truth, the system inherits the responsibility of being right, right now.
That’s why the harder question isn’t “how fast can my pipeline run?” but “can I defend the decisions my systems are already making?”
This was the thread running through Rethinking Real Time: What Today’s Streaming Leaders Know That Legacy Vendors Don’t. If you didn’t catch it, the replay is worth a look. And if you’re ready to test your own stack against these realities, Striim is already working with enterprises to design for decision-time. Book a call with a Striim expert to find out more.
]]> https://www.striim.com/blog/when-does-data-become-a-decision/feed/ 0 SQL Server Change Data Capture: How It Works & Best Practices https://www.striim.com/blog/sql-server-change-data-capture-cdc-methods-how-striim-captures-change-data-faster/ https://www.striim.com/blog/sql-server-change-data-capture-cdc-methods-how-striim-captures-change-data-faster/#respond Wed, 05 Nov 2025 22:58:41 +0000 https://www.striim.com/?p=35584 If you’re reading this, there’s a chance you need to send real-time data from SQL Server for cloud migration, operational reporting or agentic AI. How hard can it be?The answer lies in the transition. Capturing changes isn’t difficult in and of itself; it’s the act of doing so at scale without destabilizing your production environment. While SQL Server provides native Change Data Capture (CDC) functionality, making it reliable, efficient, and low-impact in a modern hybrid-cloud architecture can be challenging. If you’re looking for a clear breakdown of what SQL Server CDC is, how it works, and how to build a faster, more scalable capture strategy, you’re in the right place. This guide will cover the methods, the common challenges, and the modern tooling required to get it right.
What is SQL Server Change Data Capture (CDC)?
Change Data Capture (CDC) is a technology that identifies and records row-level changes—INSERTs, UPDATEs, and DELETEs—in SQL Server tables. It captures these changes as they happen and makes them available for downstream systems, all without requiring modifications to the source application’s tables. This capability enables businesses to feed live analytics dashboards, execute zero-downtime cloud migrations, and maintain audit trails for compliance. In today’s economy, businesses can no longer tolerate the delays of nightly or even hourly batch jobs. Real-time visibility is essential for fast, data-driven decisions. At a high level, SQL Server’s native CDC works by reading the transaction log and storing change information in dedicated system tables. While this built-in functionality provides a starting point, scaling it reliably across a complex hybrid or cloud architecture requires a clear strategy and, often, specialized tooling to manage performance and operational overhead.
Where SQL Server CDC Fits in the Modern Data Stack
Change Data Capture should not be considered an isolated feature, but a critical puzzle piece within a company’s data architecture. It functions as the real-time “on-ramp” that connects transactional systems (like SQL Server) to the cloud-native and hybrid platforms that power modern business. CDC is the foundational technology for a wide range of critical use cases, including:
Real-time Analytics: Continuously feeding cloud data warehouses (like Snowflake, BigQuery, or Databricks) and data lakes to power live, operational dashboards.
Cloud & Hybrid Replication: Enabling zero-downtime migrations to the cloud or synchronizing data between on-premises systems and multiple cloud environments.
Data-in-Motion AI: Powering streaming applications and AI models with live data for real-time predictions, anomaly detection, and decisioning.
Microservices & Caching: Replicating data to distributed caches or event-driven microservices to ensure data consistency and high performance.
How SQL Server Natively Handles Change Data Capture
SQL Server provides built-in CDC features (available in Standard, Enterprise, and Developer editions) that users must enable on a per-table basis. Once enabled, the native process relies on several key components:
The Transaction Log: This is where SQL Server first records all database transactions. The native CDC process asynchronously scans this log to find changes related to tracked tables.
Capture Job (sys.sp_cdc_scan): A SQL Server Agent job that reads the log, identifies the changes, and writes them to…
Change Tables: For each tracked source table, SQL Server creates a corresponding “shadow table” (e.g., cdc.dbo_MyTable_CT) to store the actual change data (the what, where, and when) along with metadata.
Log Sequence Numbers (LSNs): These are used to mark the start and end points of transactions, ensuring changes are processed in the correct order.
Cleanup Job (sys.sp_cdc_cleanup_job): Another SQL Server Agent job that runs periodically to purge old data from the change tables based on a user-defined retention policy. While this native system offers a basic form of CDC, it was not designed for the high-volume, low-latency demands of modern cloud architectures. The SQL Server Agent jobs and the constant writing to change tables introduce performance overhead (added I/O and CPU) that can directly impact your production database, especially at scale.
How Striim MSJET Handles SQL Server Change Data Capture
Striim’s MSJET provides high-performance, log-based CDC for SQL Server without relying on triggers or shadow tables. Unlike native CDC, it eliminates the overhead of SQL Server Agent jobs and intermediate change tables. The MSJET process relies on several key components:
The Transaction Log: MSJET reads directly from SQL Server’s transaction log—including via fn_dblog—to capture all committed INSERT, UPDATE, and DELETE operations in real time.
Log Sequence Numbers (LSNs): MSJET tracks LSNs to ensure changes are processed in order, preserving transactional integrity and exactly-once delivery.
Pipeline Processing: As changes are read from the log, MSJET can filter, transform, enrich, and mask data in-flight before writing to downstream targets.
Schema Change Detection: MSJET automatically handles schema modifications such as new columns or altered data types, keeping pipelines resilient without downtime.
Checkpointing and Retention: MSJET internally tracks log positions and manages retention, without relying on SQL Server’s capture or cleanup jobs, which consume disk space, I/O, and CPU resources.
Key Advantage: Because MSJET does not depend on shadow tables or SQL Server Agent jobs, it avoids the performance overhead, storage consumption, and complexity associated with native CDC. This enables high-throughput, low-latency CDC suitable for enterprise-scale, real-time streaming to cloud platforms such as Snowflake, BigQuery, Databricks, and Kafka.
Common Methods for Capturing Change Data from SQL Server
SQL Server provides several methods for capturing change data, each with different trade-offs in performance, latency, operational complexity, and scalability. Choosing the right approach is essential to achieve real-time data movement without overloading the source system.
Method Performance Impact Latency Operational Complexity Scalability Polling-Based High High (Minutes) Low Low Trigger-Based Very High Low High Low Log-Based Very Low Low (Seconds/Sub-second) Moderate to Low High Polling-Based Change Capture
How it works: The polling method periodically queries source tables to detect changes (for example, SELECT * FROM MyTable WHERE LastModified > ?). This approach is simple to implement but relies on repetitive full or incremental scans of the data.
The downside: Polling is highly resource-intensive, putting load on the production database with frequent, heavy queries. It introduces significant latency, is never truly real-time, and often fails to capture intermediate updates or DELETE operations without complex custom logic.
The Striim advantage: Striim eliminates the inefficiencies of polling by capturing changes directly from the transaction log. This log-based approach ensures every insert, update, and delete is captured in real time with minimal source impact—delivering reliable, low-latency data streaming at scale.
Trigger-Based Change Capture
How it works: This approach uses database triggers (DML triggers) that fire on every INSERT, UPDATE, or DELETE operation. Each trigger writes the change details into a separate “history” or “log” table for downstream processing.
The downside: Trigger-based CDC is intrusive and inefficient. Because triggers execute as part of the original transaction, they increase write latency and can quickly become a performance bottleneck—especially under heavy workloads. Triggers also add development and maintenance complexity, and are prone to breaking when schema changes occur.
The Striim advantage: Striim completely avoids trigger-based mechanisms. By capturing changes directly from the transaction log, Striim delivers a non-intrusive, high-performance solution that preserves source system performance while providing scalable, real-time data capture.
Shadow Table (Native SQL CDC)
How it works: SQL Server’s native Change Data Capture (CDC) feature uses background jobs to read committed transactions from the transaction log and store change information in system-managed “shadow” tables. These tables record before-and-after values for each change, allowing downstream tools to query them periodically for new data.
The downside: While less intrusive than triggers, native CDC still introduces overhead on the source system due to the creation and maintenance of shadow tables. Managing retention policies, cleanup jobs, and access permissions adds operational complexity. Latency is also higher compared to direct log reading, and native CDC often struggles to scale efficiently for high-volume workloads.
The Striim advantage: Striim supports native SQL CDC for environments where it’s already enabled, but it also offers a superior alternative through its MSJET log-based reader. MSJET delivers the same data with lower latency, higher throughput, and minimal operational overhead—ideal for real-time, large-scale data integration.
Log-Based (MSJET)
How it works:
Striim’s MSJET reader captures change data directly from SQL Server’s transaction log, bypassing the need for triggers or shadow tables. This approach reads the same committed transactions that SQL Server uses for recovery, ensuring every INSERT, UPDATE, and DELETE is captured accurately and in order.
The downside:
Implementing log-based CDC natively can be complex, as it requires a deep understanding of SQL Server’s transaction log internals and careful management of log sequence numbers and recovery processes. However, when done right, it provides the most accurate and efficient form of change data capture.
The Striim advantage:
MSJET offers high performance, low impact, and exceptional scalability—supporting CDC rates of up to 150+ GB per hour while maintaining sub-second latency. It also automatically handles DDL changes, ensuring continuous, reliable data capture without manual intervention. This makes MSJET the most efficient and enterprise-ready option for SQL Server change data streaming.
Challenges of Managing Change Data Capture at Scale
Log-based CDC is the gold standard for accuracy and performance, but managing it at enterprise scale introduces new operational challenges. As data volumes, change rates, and schema complexity grow, homegrown or basic CDC solutions often reach their limits, impacting reliability, performance, and maintainability.
Handling Schema Changes and Schema Drift
The pain point: Source schemas evolve constantly—new columns are added, data types change, or fields are deprecated. These “schema drift” events often break pipelines, cause ingestion errors, and lead to downtime or data inconsistency.
Striim’s advantage: Built with flexibility in mind, Striim’s MSJET engine automatically detects schema changes in real time and propagates them downstream without interruption. Whether the target needs a structural update or a format transformation, MSJET applies these adjustments dynamically, maintaining full data continuity with zero downtime.
Performance Overhead and System Impact
The pain point: Even SQL Server’s native log-based CDC introduces operational overhead. Its capture and cleanup jobs consume CPU, I/O, and storage, while writing to change tables can further slow down production workloads.
When it becomes critical: As transaction volumes surge or during peak business hours, this additional load can impact response times and force trade-offs between production performance and data freshness.
Striim’s advantage: MSJET is engineered for high performance and low impact. By reading directly from the transaction log without relying on SQL Server’s capture or cleanup jobs, it minimizes system load while sustaining throughput of 150+ GB/hour. All CDC processing occurs within Striim’s distributed, scalable runtime, protecting your production SQL Server from performance degradation.
Retention, Cleanup, and Managing CDC Metadata
The pain point: Native CDC requires manual maintenance of change tables, including periodic cleanup jobs to prevent unbounded growth. Misconfigured or failed jobs can lead to bloated tables, wasted storage, and degraded query performance.
Striim’s advantage: MSJET removes this burden entirely. It manages retention, checkpointing, and log positions internally, no SQL Server Agent jobs, no cleanup scripts, no risk of data buildup. Striim tracks its place in the transaction log independently, ensuring reliability and simplicity at scale.
Security, Governance, and Audit Considerations
The pain point: Change data often includes sensitive information, such as PII, financial records, or health data. Replicating this data across hybrid or multi-cloud environments can introduce significant security, compliance, and privacy risks if not properly managed.
Striim’s advantage: Striim provides a comprehensive, enterprise-grade data governance framework. Its Sherlock agent automatically detects sensitive data, while Sentinel masks, tags, and encrypts it in motion to enforce strict compliance. Beyond security, Striim enables role-based access control (RBAC), filtering, data enrichment, and transformation within the pipeline—ensuring only the data that is required is written to downstream targets. Combined with end-to-end audit logging, these capabilities give organizations full visibility, control, and protection over their change data streams.
Accelerate and Simplify SQL Server CDC with Striim
Relying on native SQL Server CDC tools or DIY pipelines comes with significant challenges: performance bottlenecks, brittle pipelines, schema drift, and complex maintenance. These approaches were not built for real-time, hybrid-cloud environments, and scaling them often leads to delays, errors, and operational headaches. Striim is purpose-built to overcome these challenges. It is an enterprise-grade platform that delivers high-performance, log-based CDC for SQL Server, combining reliability, simplicity, and scalability. With Striim, you can:
Capture data with minimal impact: MSJET reads directly from the transaction log, providing real-time change data capture without affecting production performance.
Handle schema evolution automatically: Detect and propagate schema changes in real time with zero downtime, eliminating a major source of pipeline failure.
Process data in-flight: Use a familiar SQL-based language to filter, transform, enrich, and mask sensitive data before it reaches downstream systems.
Enforce security and governance: Leverage Sherlock to detect sensitive data and Sentinel to mask, tag, and encrypt it in motion. Combined with RBAC, filtering, and audit logging, you maintain full control and compliance.
Guarantee exactly-once delivery: Ensure data integrity when streaming to cloud platforms like Snowflake, Databricks, BigQuery, and Kafka.
Unify integration and analytics: Combine CDC with real-time analytics to build a single, scalable platform for data streaming, processing, and insights.
Stop letting the complexity of data replication slow your business. With Striim, SQL Server CDC is faster, simpler, and fully enterprise-ready. Interested in a personalized walkthrough of Striim’s SQL Server CDC functionality? Please schedule a demo with one of our CDC experts! Alternatively you can try Striim for free.
]]> https://www.striim.com/blog/sql-server-change-data-capture-cdc-methods-how-striim-captures-change-data-faster/feed/ 0 How to Migrate Data from MySQL to Azure Database for MySQL https://www.striim.com/blog/how-to-migrate-data-from-mysql-to-azure-database-for-mysql/ https://www.striim.com/blog/how-to-migrate-data-from-mysql-to-azure-database-for-mysql/#respond Mon, 03 Nov 2025 17:18:08 +0000 https://www.striim.com/?p=88637 For many data teams, migrating MySQL workloads to Azure Database for MySQL is a critical step in modernizing their data platform, but maintaining uptime, preserving data integrity, and validating performance during the process can be complex.
With Striim and Microsoft Azure, those challenges become manageable. Striim’s log-based Change Data Capture (CDC) continuously streams every MySQL transaction into Azure Database for MySQL, enabling zero-data-loss replication, real-time validation, and minimal impact on live applications.
As part of the Microsoft Unlimited Database Migration Program, this joint solution helps organizations accelerate and de-risk their path to Azure. By combining proven migration tooling, partner expertise, and architectural guidance, together, Striim and Microsoft simplify every stage of the move.
This tutorial walks through the key steps and configurations to successfully migrate from MySQL to Azure Database for MySQL using Striim.
Why Use Striim for Continuous Migration
Through the Unlimited Database Migration Program, Microsoft customers gain unlimited Striim licenses to migrate as many databases as they need at no additional cost. Highlights and benefits of the program include:
Zero-downtime, zero-data-loss migrations. Supported sources include SQL Server, MongoDB, Oracle, MySQL, PostgreSQL, Sybase, and Cosmos. Supported targets include Azure Database for MySQL, Azure Database for PostgreSQL, Azure Database for CosmosDB, and Azure Database for MariaDB.
Mission-critical, heterogeneous workloads supported. Applies for SQL, Oracle, NoSQL, OSS.
Drives faster AI adoption. Once migrated, data is ready for real-time analytics & AI.
In this case, Striim enables continuous, log-based Change Data Capture (CDC) from MySQL to Azure Database for MySQL. Instead of relying on periodic batch jobs, Striim reads directly from MySQL binary logs (binlogs) and streams transactions to Azure in real time.
Using the architecture and configuration steps outlined below, this approach minimizes impact on production systems and ensures data consistency even as new transactions occur during migration.
Architecture Overview
This specific setup includes three components:
Source: an existing MySQL database, hosted on-premises or in another cloud.
Processing layer: Striim, deployed in Azure for low-latency data movement.
Target: Azure Database for MySQL (Flexible Server recommended).
Data flows securely from MySQL → Striim → Azure Database for MySQL through ports 3306 and 5432. Private endpoints or Azure Private Link are recommended for production environments to avoid public internet exposure.
Preparing the MySQL Source
Before streaming can begin, enable binary logging and create a replication user with read access to those logs:
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'striim_user'@'%';
Set the binlog format to ROW and ensure logs are retained long enough to handle any temporary network interruption.
In Striim, use the MySQL Reader component to connect to the source. This reader consumes binlogs directly, so overhead on the production system remains in the low single-digit percentage range.
You can find detailed configuration guidance in Striim’s MySQL setup documentation.
Configuring the Azure MySQL Target
Before starting the pipeline, make sure target tables exist in Azure Database for MySQL. Striim supports two methods:
Schema Conversion Utility (CLI): automatically generates MySQL DDL statements.
Wizard-based creation: defines and creates tables directly through the Striim UI.
Create a MySQL user with appropriate privileges:
CREATE USER striim_user WITH PASSWORD 'strongpassword'; GRANT CONNECT, CREATE, INSERT, UPDATE, DELETE ON DATABASE targetdb TO striim_user;
The Striim environment needs network access to the MySQL instance over port 5432. Using a private IP or Azure Private Endpoint helps maintain compliance and security best practices.
Building the Migration Pipeline
A complete Striim migration includes three coordinated stages:
Schema Migration – creates tables and schemas in the target.
Initial Load – bulk-loads historical data from MySQL to Azure Database for MySQL.
Change Data Capture (CDC) – continuously streams live transactions to keep the systems in sync.
During the initial load, Striim copies historical data using a Database Reader and Database Writer. Once complete, you can start the CDC pipeline to apply real-time updates until MySQL and Azure Database for MySQL are fully synchronized. Note that Striim automatically maps compatible data types during initial load and continuous replication.
When ready, pause writes to MySQL, validate record counts, and cut over to Azure with zero data loss. Follow Striim’s switch-over guide for sequencing the transition safely.
Working in Striim
You can build pipelines in Striim using several methods:
Wizards: pre-built templates that guide you through setup for common source/target pairs such as MySQL → Azure Database for MySQL.
Visual Designer: drag-and-drop components for custom data flows.
TQL scripts: Striim’s language for defining applications programmatically, suitable for CI/CD automation.
Each Striim application is backed by a TQL file, which can be version-controlled and deployed via REST API for repeatable infrastructure-as-code workflows. Below is a step-by-step demo of what you can expect.
Adding Transformations and Smart Pipelines
Beyond 1:1 replication, you can apply transformations to enrich or reshape data before writing to Azure. Striim supports in-memory processing through continuous SQL queries or custom Java functions.
For example, you can append operational metadata:
SELECT *, CURRENT_TIMESTAMP() AS event_time, OpType() AS operation FROM MySQLStream;
These Smart Data Pipelines allow teams to incorporate auditing, deduplication, or lightweight analytics without creating separate ETL jobs—streamlining modernization into a single migration flow.
Performance Expectations
In joint Striim and Microsoft testing, results typically show:
1 TB historical load: completed in 4–6 hours
Ongoing CDC latency: sub-second for inserts, updates, and deletes
Throughput depends on schema complexity, hardware configuration, and network performance. For best results, deploy Striim in the same Azure region as your Azure Database for MySQL target and allocate sufficient CPU and memory resources.
Support and Enablement
The Microsoft Unlimited Database Migration Program is designed specifically to provide customers direct access to Striim’s field expertise throughout the migration process.
From end-to-end, you can expect:
Onboarding and ongoing support, including installation kits and walkthroughs.
Higher-tier service packages are available as well.
Direct escalation paths to Striim for issue resolution and continuous assistance during migration and replication.
Professional services and funding flexibility, such as ECIF coverage for partner engagements, cutover or weekend go-live standby, and pre-approved service blocks to simplify SOW approvals.
Together, these resources ensure migrations from MySQL to Azure Database for MySQL are fully supported from initial enablement through post-cutover operations, backed by Microsoft and Striim’s combined field teams.
Accelerate Your Migration Journey with Microsoft’s Unlimited Database Migration Program
With Striim and Microsoft, moving from MySQL to Azure Database for MySQL is no longer a complex, high-risk process—it’s an engineered pathway to modernization. Through the Microsoft Unlimited Database Migration Program, you can access partner expertise, joint tooling, and migration credits to move data workloads to Azure quickly and securely at no extra cost to you.
Whether your goal is one-time migration or continuous hybrid replication, Striim’s CDC engine, combined with Azure’s managed MySQL service, ensures every transaction lands with integrity. Start your modernization journey today by connecting with your Microsoft representative or visiting https://go2.striim.com/demo.